
A Visual Guide to Gemma 4 12B
A unified, encoder-free multimodal model!

A new Gemma 4 model has been released and it’s an interesting one. There was an empty spot between the E4B and 26B A4B that needed to be filled and a 12B model fits nicely there. However, it wouldn’t be Google DeepMind without trying to do something special with that model and sharing it with the public.
So what is different with Gemma 4 12B?
It is encoder-free!
I’m going to be honest with you. The first time I heard “encoder-free” I was confused. Aren’t generative LLMs these days decoder-only anyway? It took me a minute to realize that the encoders for audio and video understanding were actually removed in this model but still had those multimodal capabilities.
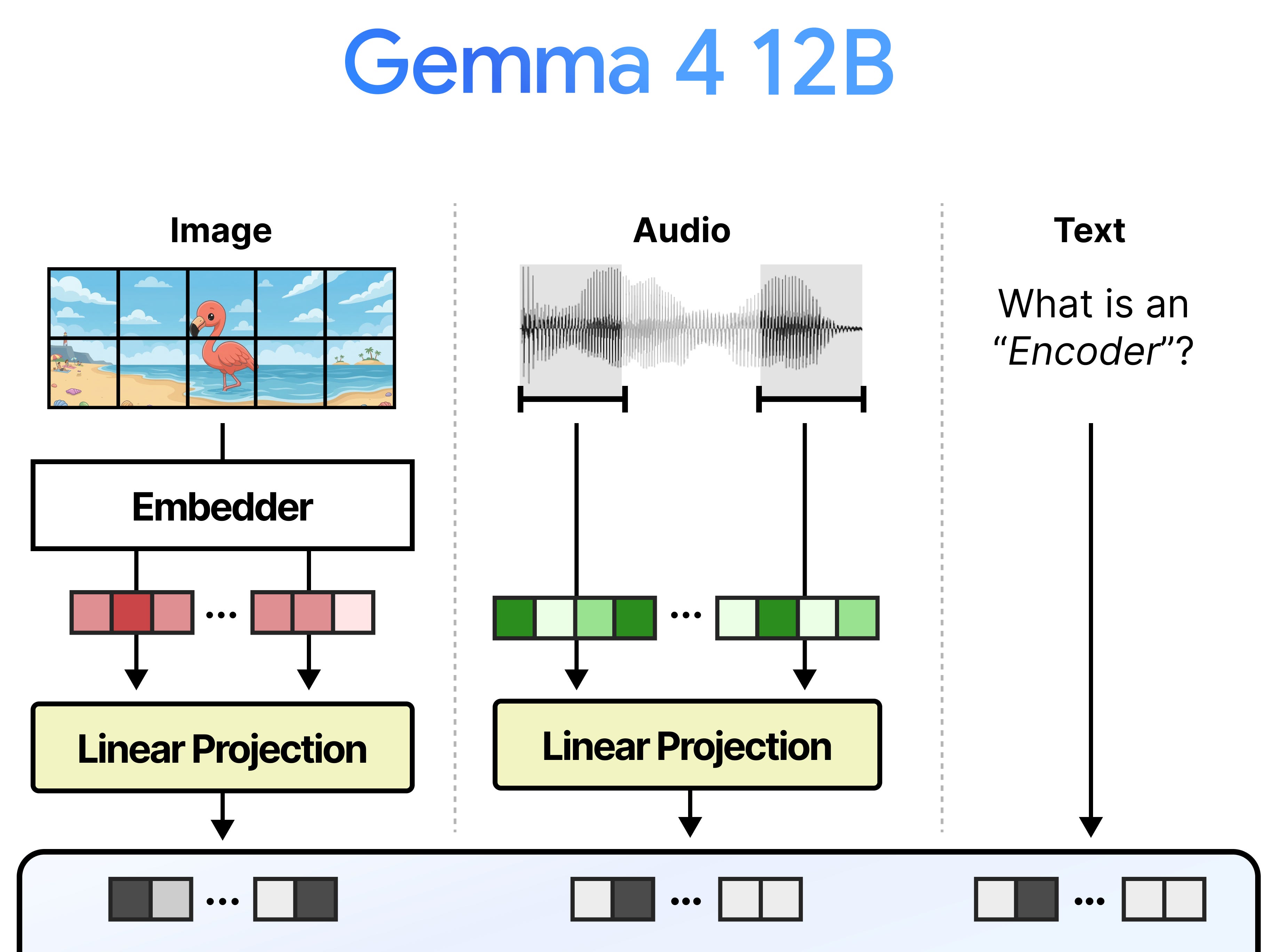
The removal of the encoders, which are typically in charge of making sense of the multimodal inputs, places the burden of making sense of all outputs on the LLM. Although the model is encoder-free, all modalities are now unified within the LLM. Instead of the model having to wait for the encoders to finish processing the audio and image inputs, the LLM can get started earlier processing the input and generating output!
In this guide, I want to showcase what it took to remove the vision and audio encoders and replace them with something much faster. The result, a 12B model that can handle audio and image inputs but without the need for encoders.
Encoding and Connecting Modalities
Before we explore Gemma 4 and how it was made encoder-free, let’s take a step back and discover what it generally means to connect modalities other than text to an LLM.
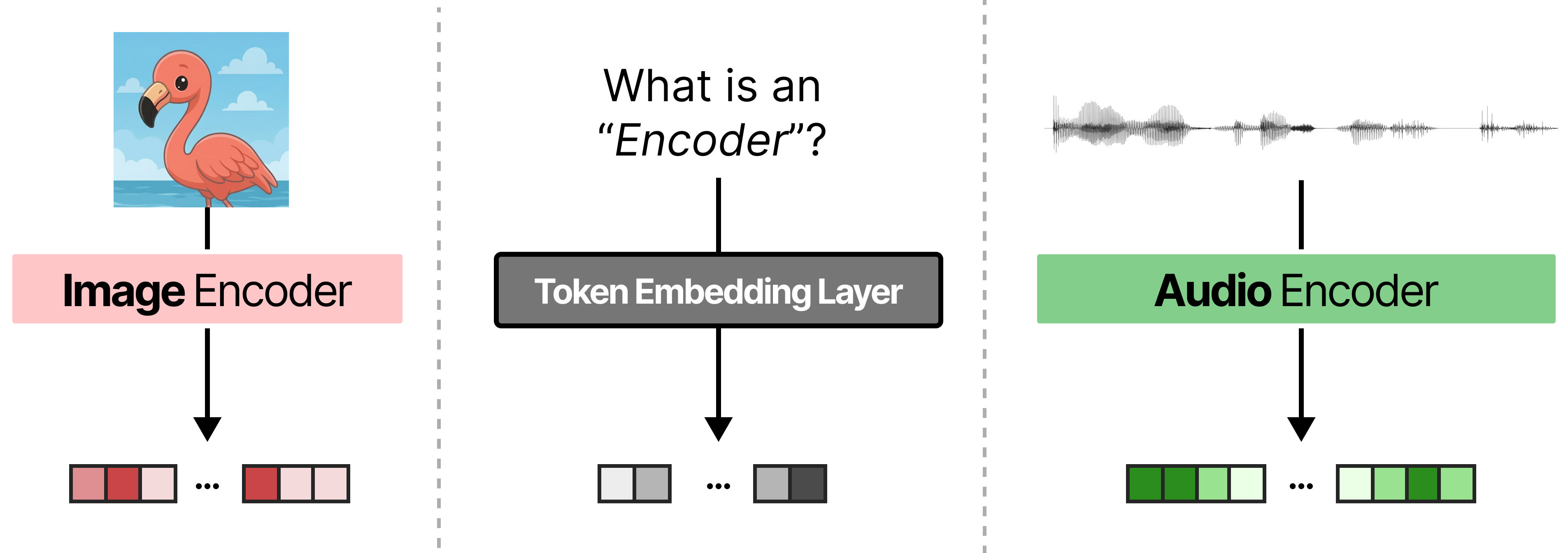
When a piece of text is given to an LLM, the LLM itself (through its token embedding layer) is in charge of splitting it up into tokens and converting them to embeddings. They are then passed to the decoder layers of the LLM which houses the attention layers used to create meaningful and contextual representations of those token embeddings.
To give an LLM the capability to understand modalities other than text, like audio and vision, much of the processing is generally not handled by the LLM. Instead, a separate encoder driven by attention is used to first process the input into embeddings. The encoder tends to be a small Transformer model and uses attention to process the input, much like the LLM would.
However, the resulting embeddings cannot be used directly by the LLM. They typically are of different dimensions and might behave differently in n-dimensional space. A common technique is to use something called a “connector”. It converts the output of an encoder to the same dimensions as the token embeddings. After all, a Large Language Model is mostly trained on text.
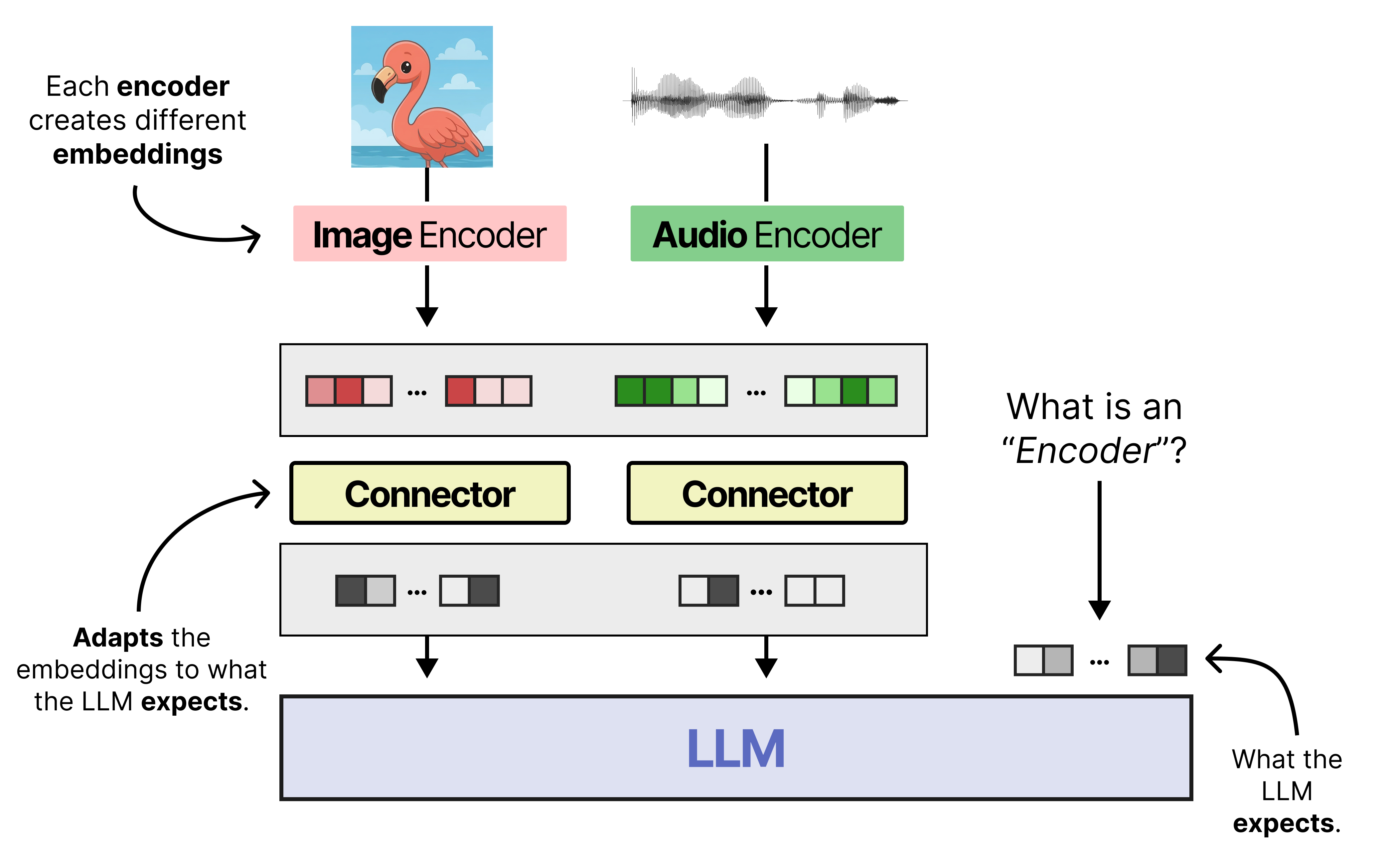
Generally, these two components are used to make LLMs multimodal. It works quite well and is used by many open-access multimodal LLMs, like Gemma 4 and Qwen 3.5.
It is not a free lunch though. The non-text encoders will need to process their inputs first before the LLM can start working. This adds some latency to the inference of these models. Moreover, it also adds quite a few parameters since the encoders are, in absolute terms, quite large.
So… What if we do not need the encoder? What if the connector is all you need?
To explore how DeepMind unified multimodal inputs, let’s first explore how the encoders in Gemma 4 work and what it took to replace them.
The Modalities of Gemma 4
Gemma 4 supports three modalities:
Text input – All models
Image input – All models
Audio input – The E2B and E4B models only
All of these modalities require a transformer-like architecture with attention to process those inputs. For the image and audio inputs, two separate transformer encoders are used to create visual and audio tokens that the LLM can use.
The Vision Encoder
Gemma 4 E2B, E4B, 26B A4B, and 31B all have a vision encoder that is used to process input images. Those vision encoders have some weight to them. For E2B and E4B, they have 150 million parameters. For 26B A4B and 31B, they have 550 million parameters.
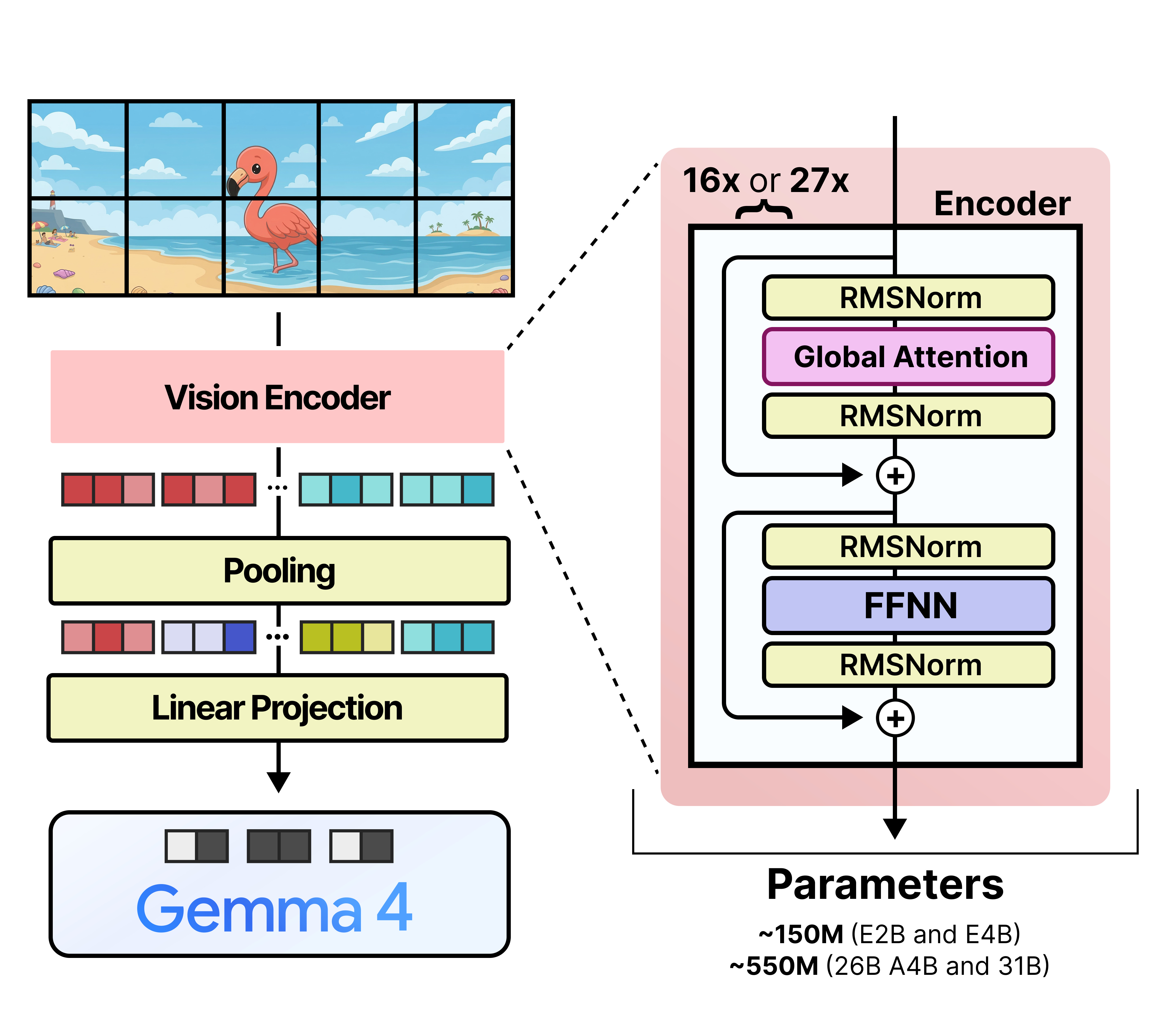
The input patches have a size of 16 by 16 pixels. After they are processed by the vision encoder, they are pooled together in a grid of 3 by 3 patches each.
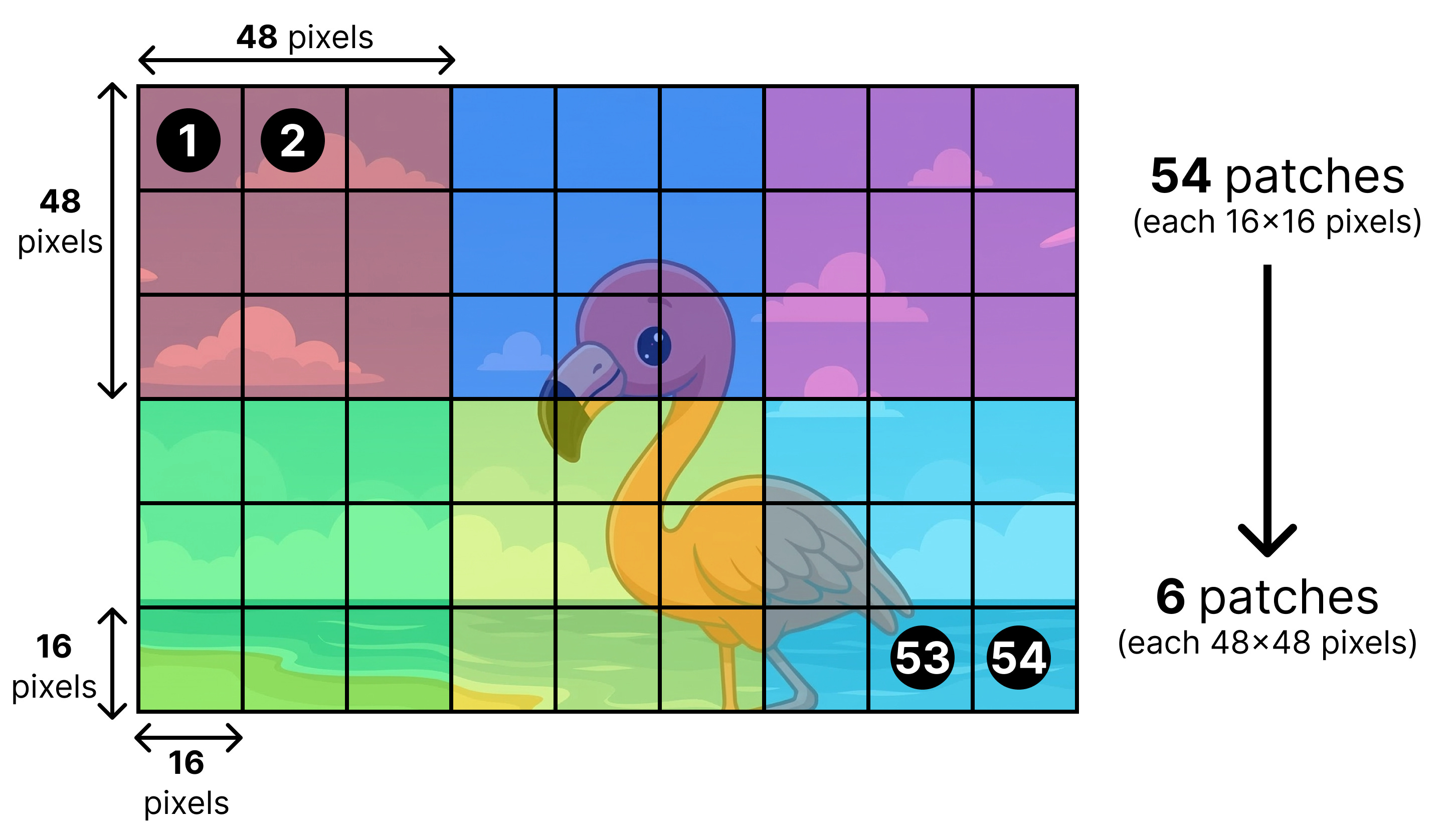
Those patch embeddings represent 48 by 48 pixels as a result of pooling the original patches together. After this pooling step, a small linear projection layer (the connector) is used to transform the patch embeddings into embeddings that are suitable to be processed by the LLM. As such, the final patch embeddings have the same shape as the token embeddings and are interleaved with the token embeddings.
The Audio Encoder
The smaller Gemma 4 models (E2B and E4B) also have an audio encoder that is used to process input audio. Like the vision encoders, these audio encoders have some weight to them. The audio encoder for E2B and E4B are the same and both have 305 million parameters.
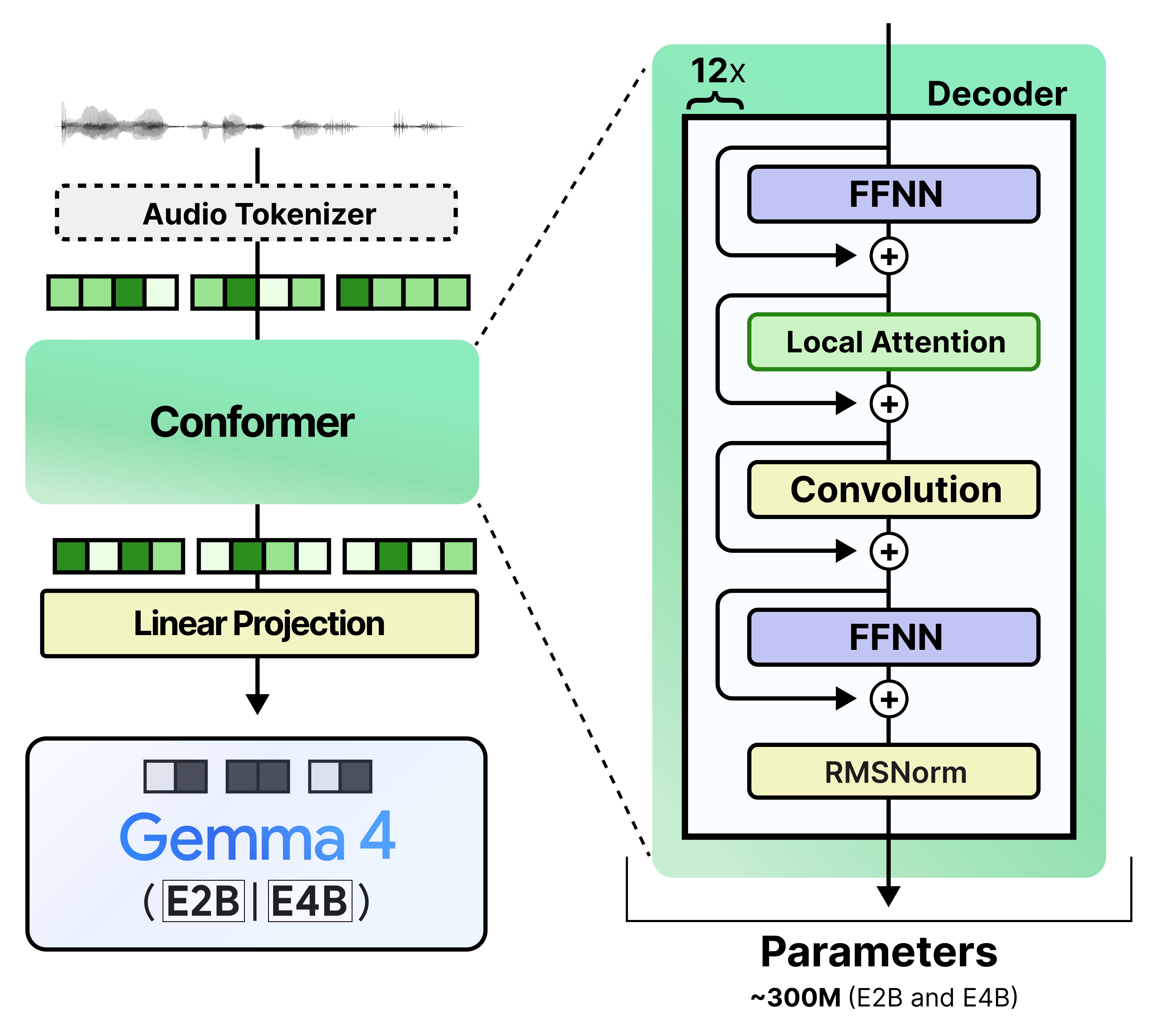
Like the vision encoder, after it processes the audio input, it projects the embeddings onto the same dimensional space as the token embeddings. The resulting audio token embeddings are interleaved with the text token embeddings.
These models, albeit relatively small compared to their corresponding Gemma 4 model, still require processing the input which increases latency and adds complexity to the entire pipeline. Moreover, when you fine-tune a Gemma 4 model, you are typically only fine-tuning the LLM itself and not its encoders. This makes it more difficult to grow the encoders with the models as you would have to fine-tune them in tandem, which adds complexity.
So what if we could do without the encoders entirely?
Making Gemma 4 12B Encoder-free
To remove the encoders and at the same time provide the community with a new model, Google DeepMind introduces the Gemma 4 12B model. The main architecture of Gemma 4 12B (looking only at the LLM itself) is rather similar to that of the 31B dense model. It uses the same decoder structure interleaving local attention with global attention in such a way that global attention is always last.
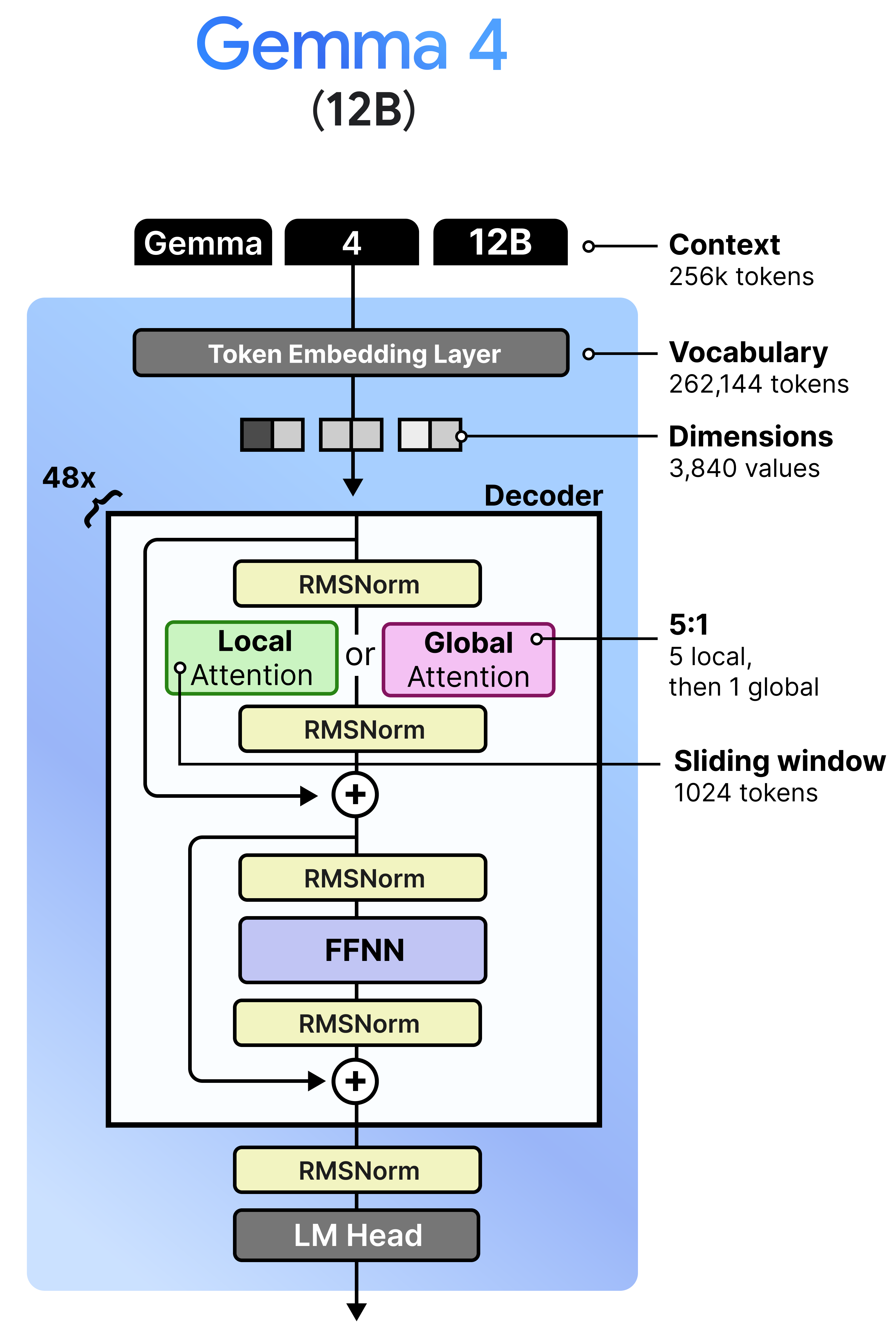
The model sits nicely between the existing E4B and 26B A4B models. That makes it suited for setups that have between 12GB and 16GB of VRAM.
Aside from the size, a big part of its offering is the removal of those somewhat chunky encoders.
Replacing The Vision Encoder
Gemma 4 12B replaces the entire vision encoder with a lightweight embedding module. Instead of running all those transformer layers (15 or 27) to extract and process visual features, the embedding module only contains a single layer to create the embeddings.
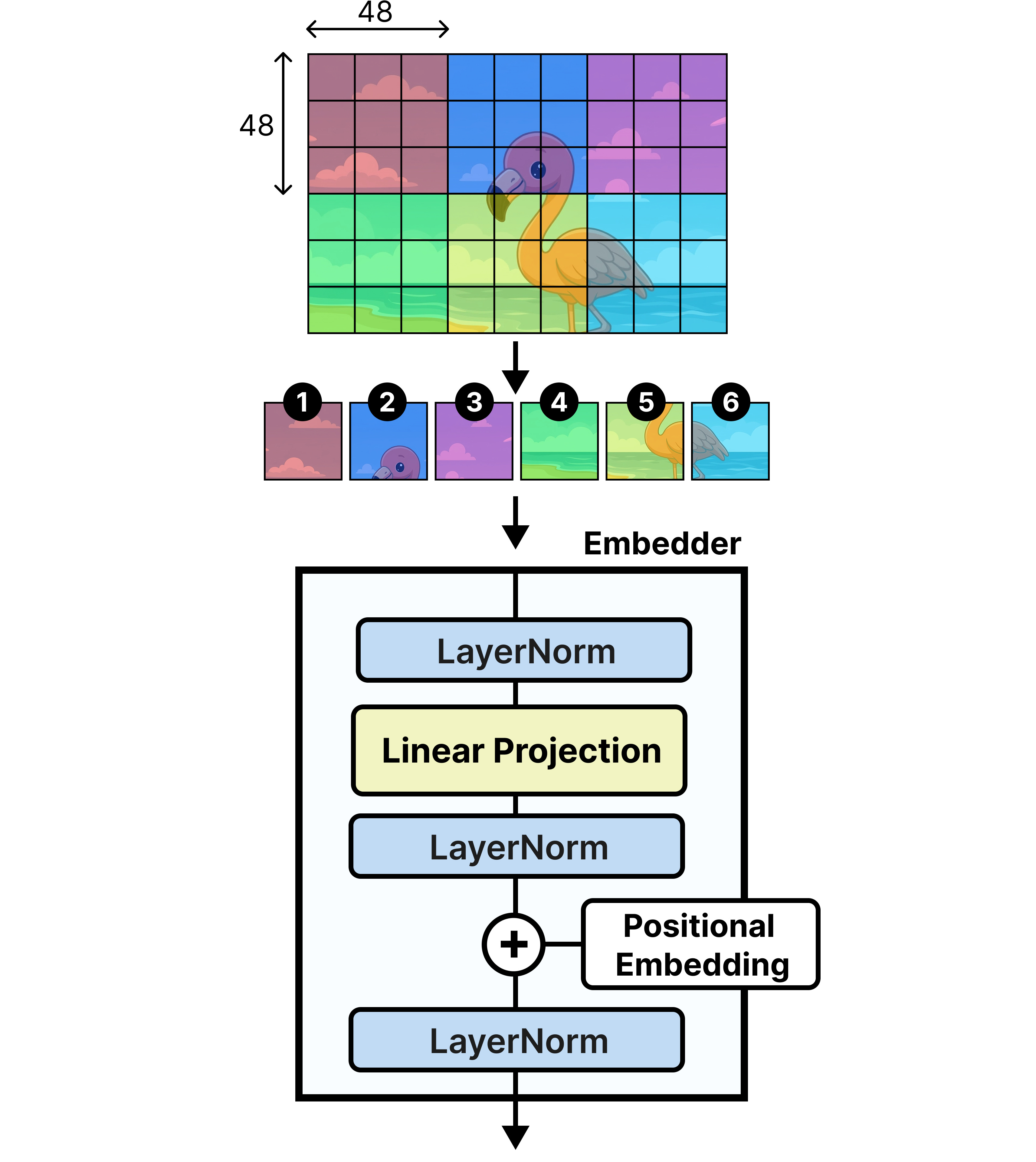
The model directly uses those 48x48 patches instead of the 16x16 patches. Although simplifying the architecture is a nice side effect, the vision encoder would have created semantically rich embeddings which isn’t the case with the embedder. So pooling the 16x16 patches into 48x48 wouldn’t have that much of an effect.
During processing of the input patches, positional information needs to be added so the LLM has an idea of where those vision tokens are located in the original image. Since the embedder is attention-free, you can’t use the same 2D-positional RoPE as is done in the vision encoder. Likewise, using the LLM’s positional encoding also wouldn’t work since it treats its inputs as a one-dimensional sequence.
Instead, you can inject spatial information in the vision token embeddings before they enter the LLM. The process is actually quite straightforward and involves two matrices:
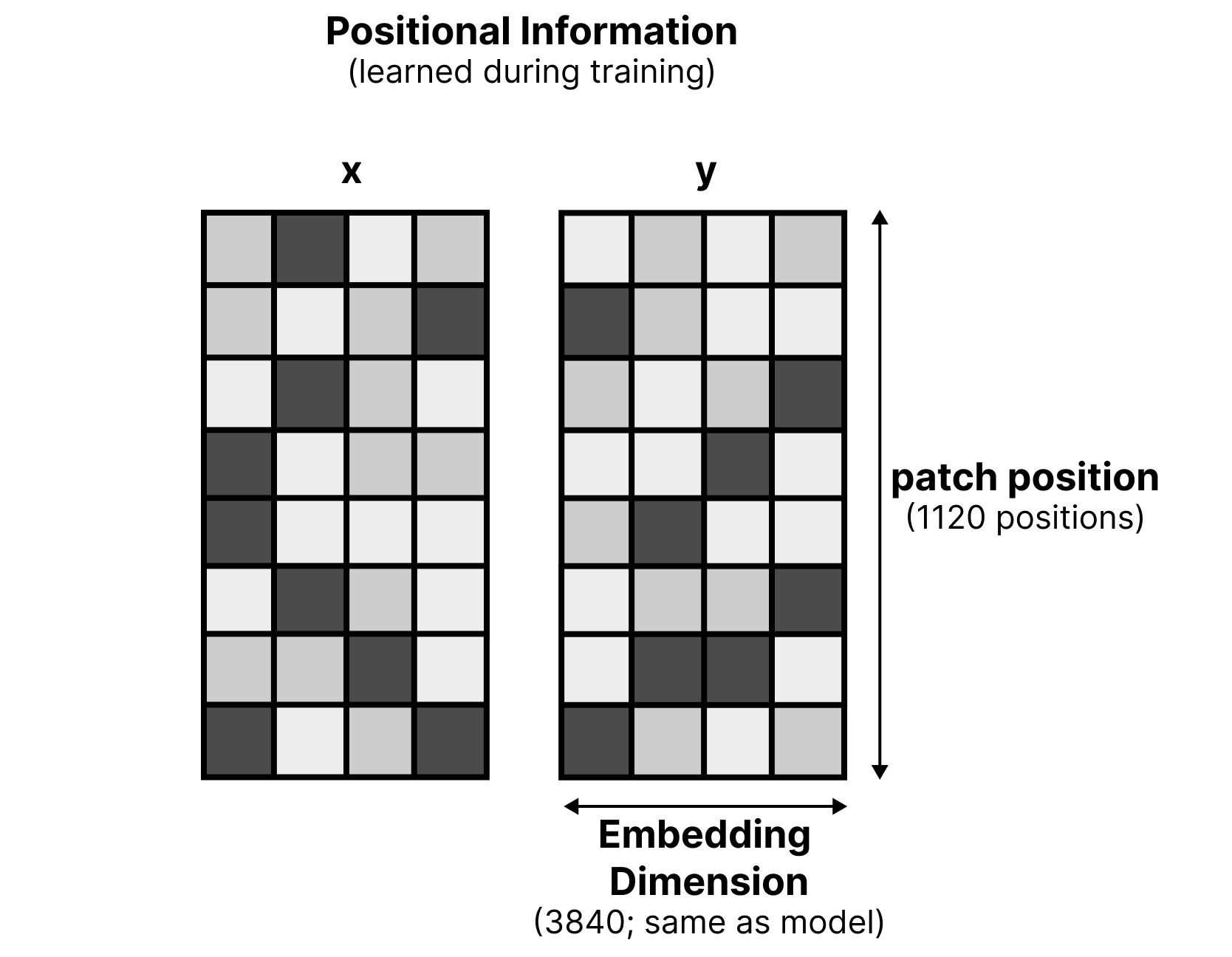
These two matrices represent the x and y coordinates of the patches. Each has a dimension of 1120 (representing the patch position) by 3840 (same as the model’s input dimensions). The patch positions represent the maximum number of patches of the input image. As with the vision encoders, the maximum number of patches can represent different ratio aspects.
The Gemma 4 models with vision encoders allow the user to select budget sizes of 70, 140, 280, 560, or 1120 tokens (also referred to as “patches”). These budget sizes represent the maximum number of patches to split an image up. More tokens means a more fine-grained perspective.
For each patch, positional embeddings are added based on their locations. Let’s go through an example. Let’s say that you have a patch at location x=2 and y=1. For both the x and y matrices, the corresponding embedding is selected. Those embeddings are then added together to create the positional embeddings that are added to each vision token embedding generated in the embedder.
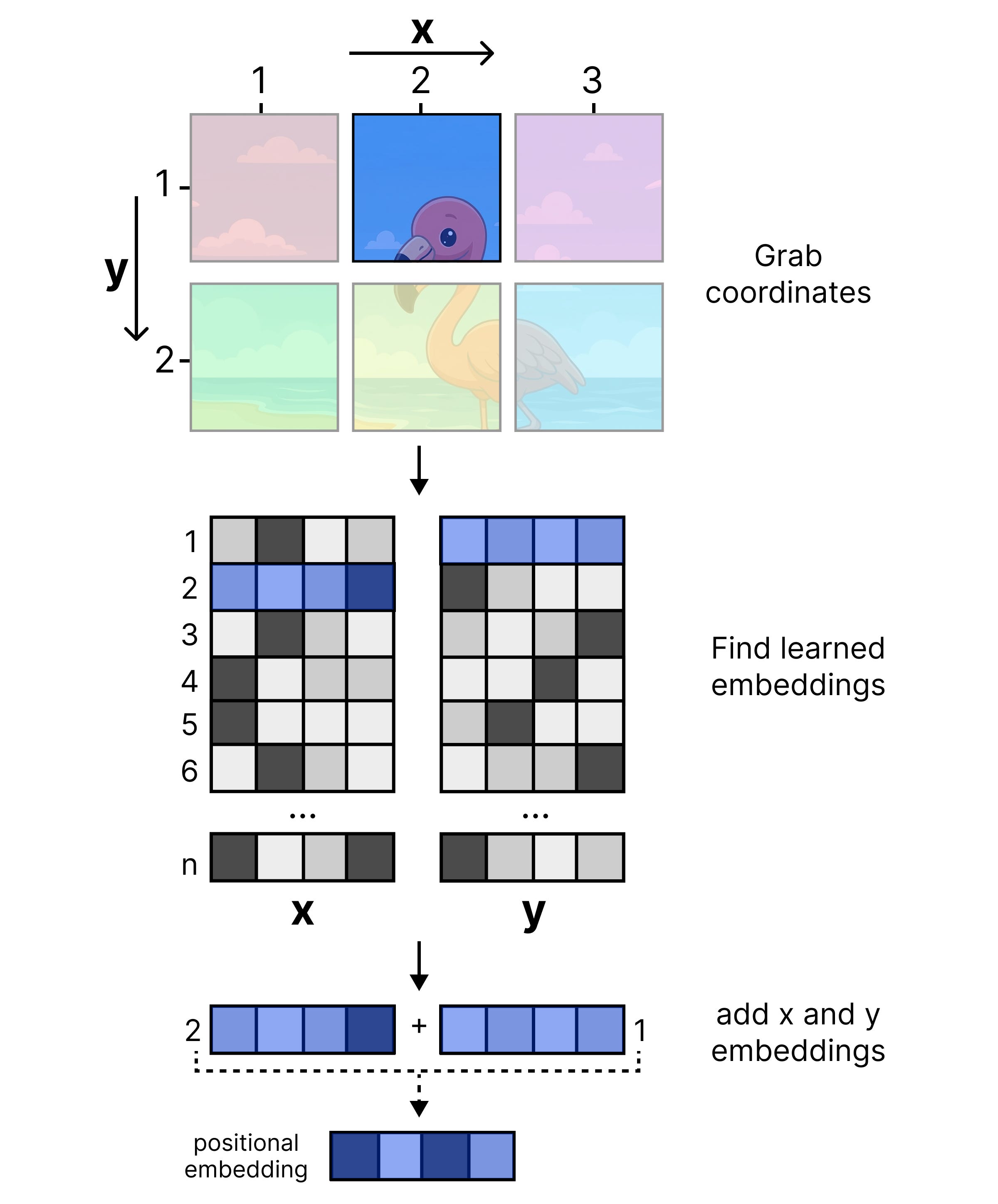
After adding the positional embeddings there’s a final LayerNorm for stability before the embeddings are projected to the dimensions that Gemma 4 12B expects.
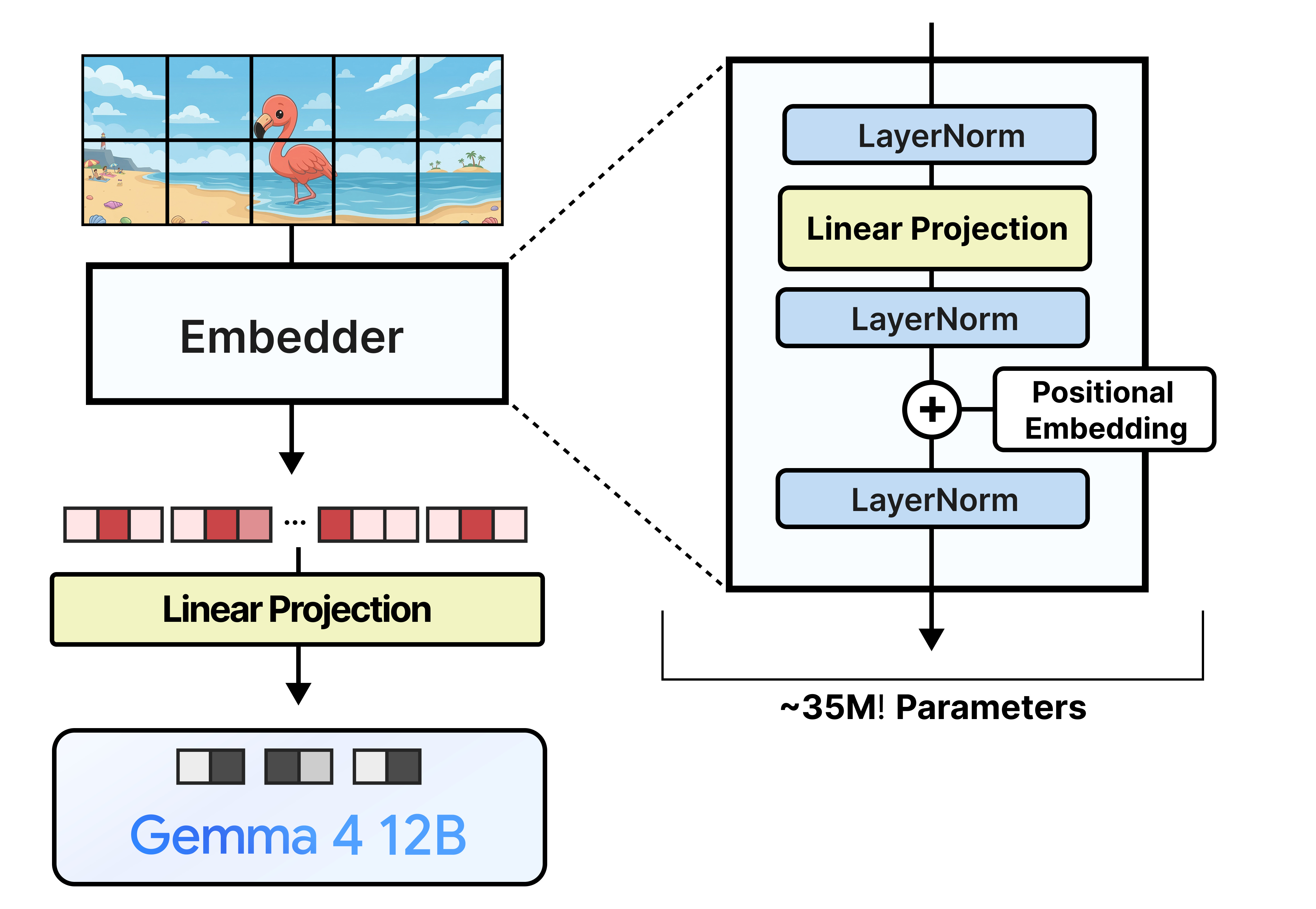
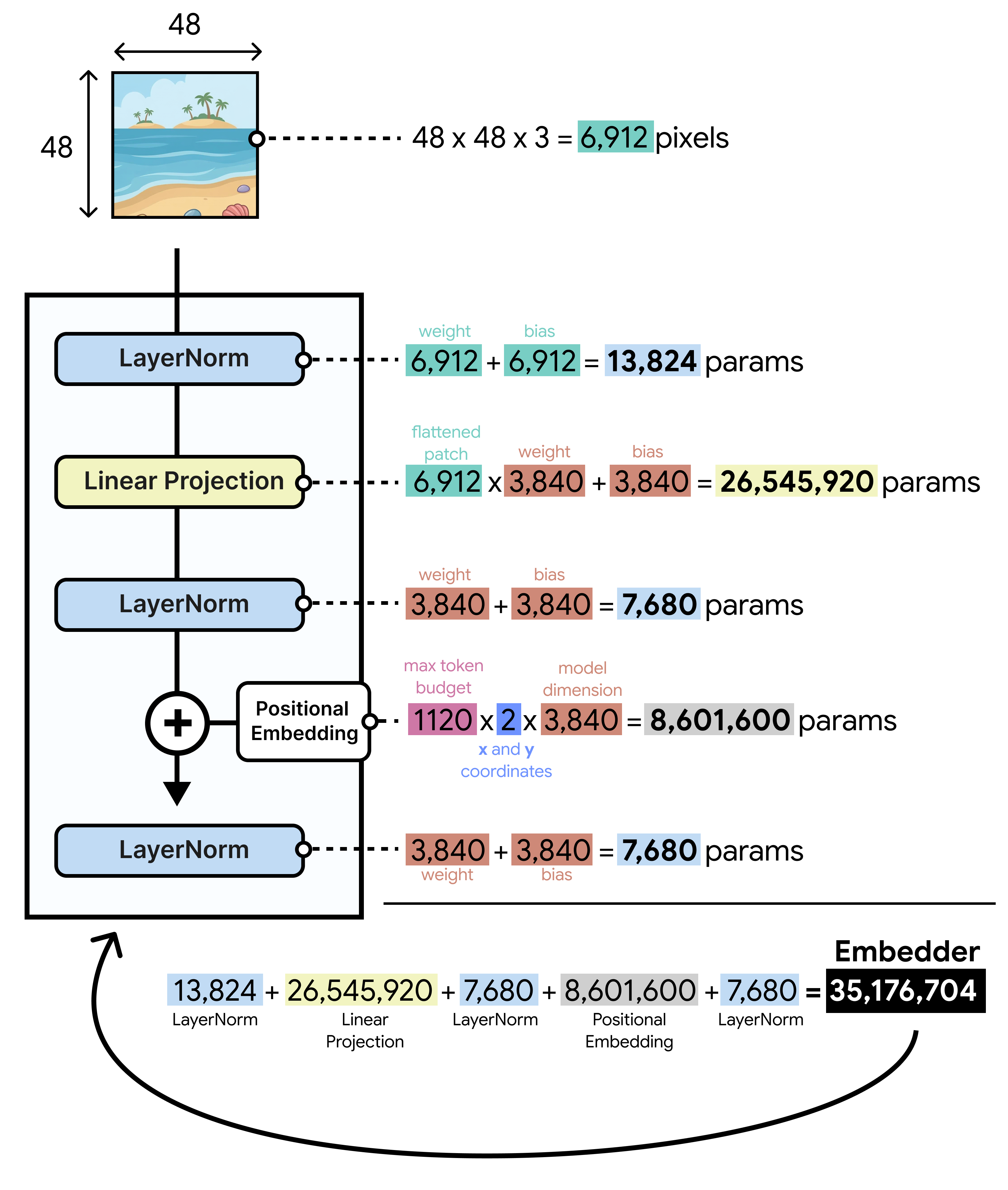
Compared to the larger models with vision encoders of 550 million parameters, the embedder only has about 35 million parameters! This is no free lunch though since the LLM now has to take over much of the processing and understanding that the vision encoder initially did, which it can learn during training.
You might wonder where the 35 million parameters come from when the model is encoder-free! The reason for this has mostly to do with projecting the image patches to the dimensionality of the LLM. Each patch has 48 x 48 x 3 = 6912 pixels that need to be projected onto the dimensions of Gemma 4 12B (3,840). Just this projection (6,912 x 3,840 + 3,840) takes up about 26 million parameters.
So the encoder didn’t shrink to 35 million parameters of attention and/or feed forward neural network weights, it’s just that there are so many pixels to project!
You might also notice that only one patch is used in the image above. Since the embedder has no attention, it processes each patch in isolation. The attention is handled by the LLM instead!
Looking at the picture below, the difference is quite large. Compared to Gemma 4 31B, the embedder is very minimal and is mostly meant to add the positional embeddings. Other than that, the embedder only has about 35 million parameters whilst the vision encoder has around 550 million!
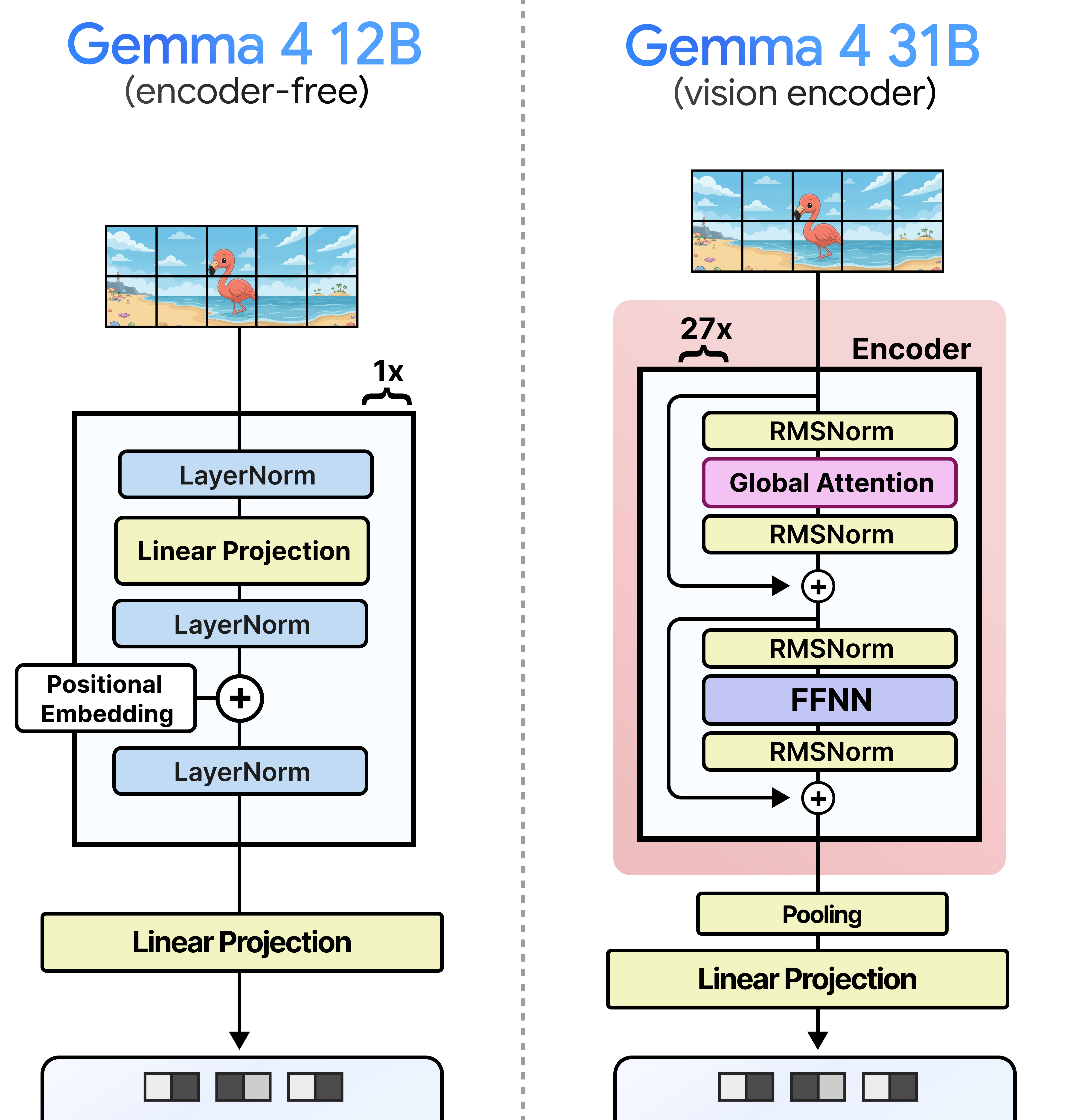
A major benefit of encoder-free models is that the vision tokens reach the LLM much faster compared to the larger vision encoders. As a result, the LLM can get started earlier processing the input and generating output!
Replacing The Audio Encoder
Replacing the audio encoder is much like was done with the vision encoder, but even simpler!
Instead of creating processed features, as is the main purpose of an encoder, the raw audio input is used directly much like the raw pixels for the embedder. With audio, this comes with a major advantage, namely that it does not need additional positional embeddings! The reason for this is that audio is already a 2-dimensional sequence and as such can be processed much like text sequences.
We first split the audio input up into sequences of 40 milliseconds. The audio sequence is recorded at 16,000 snapshots per second (16 kHz), where each sequence contains 640 values. Each value represents how high or low the sound wave is. Together these 640 values are the raw amplitude samples and represent the raw features at that sequence.
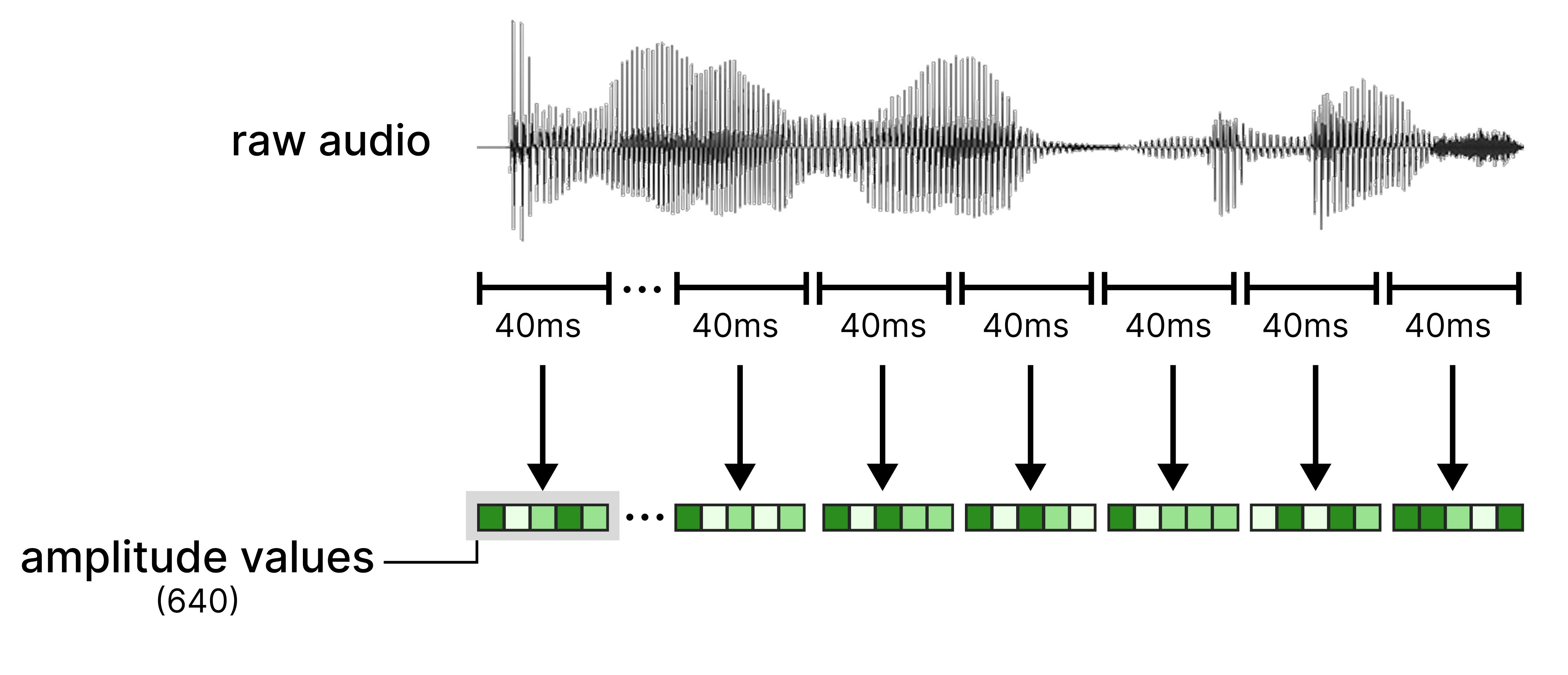
These raw features are then given to a linear projection layer so that they have the same dimensionality as Gemma 4 12B expects.
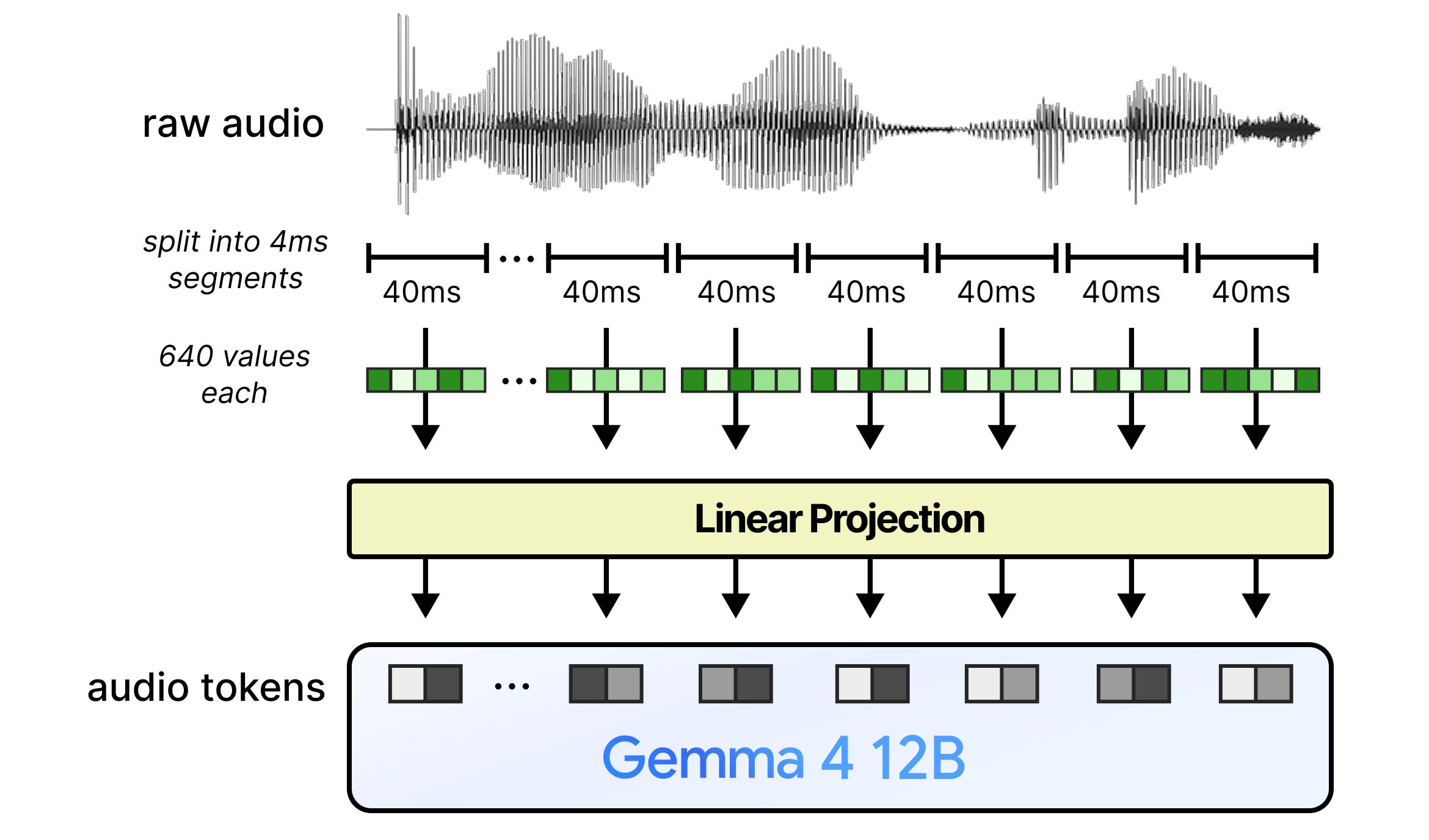
And that was it! Really, all that was needed is to remove the encoder and directly project the raw features into the same format as the text tokens.
Looking at the picture below, there is a big difference in creating audio tokens between Gemma 4 12B and Gemma 4 E4B. Gemma 4 E4B needs to tokenize the audio input and perform processing through stacked decoders. Gemma 4 12B on the other only splits and projects, that is it.
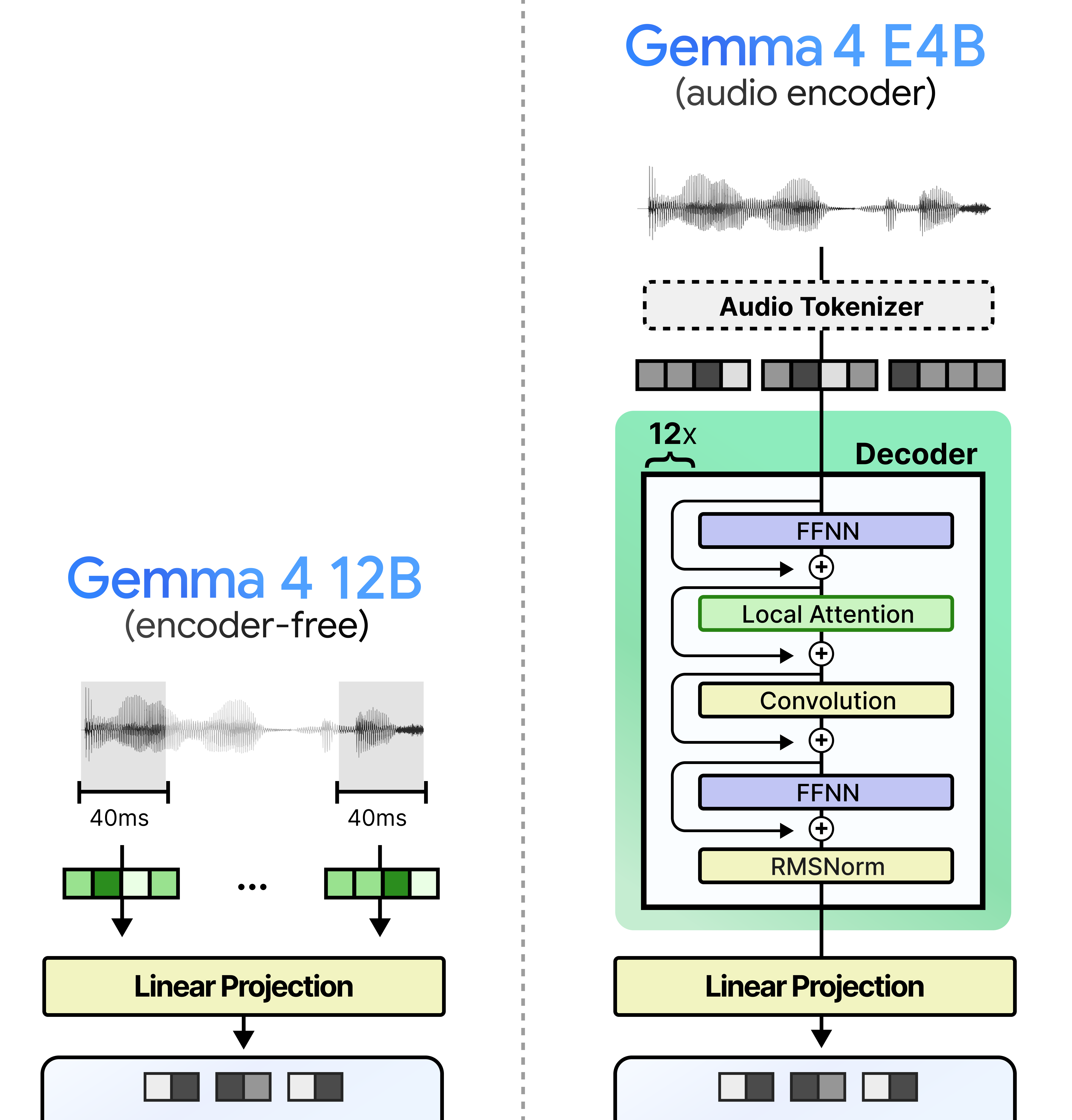
Gemma 4 12B is not just a model that fits nicely between E4B and 26B A4B, it does something different and the way it does so is quite interesting!
Conclusion
This was a great post to be working on! I thoroughly enjoy working through these new models, especially if they do something that is not only novel but also quite performant.
It is part of the reason for joining DeepMind; the research for new and exciting architectures.
I’m grateful to the wonderful people that gave feedback on this visual guide: André Susano Pinto, Andreas Peter Steiner, Michael Tschannen, Karsten Roth, Karolis Misiunas, Omar Sanseviero, and everyone that I might have forgotten ;)
However, I’m even more grateful to all of you readers! Your excitement for some of these blogs and the wish to keep it going hasn’t gone unnoticed. I will definitely be making more visual guides in the future 🎉
Nice post.. thanks!
But I am missing a very important piece of info.. benchmarks :)
what net effect did this have ? e.g. a side by side comparison between two models w and w/o the encoders.. do we need more data ? more training ? what gap we have in terms of performance
Thanks!
Awesome breakdown, thanks for this. I have couple of questions, since 2D-ROPE has been removed how does the model learn relative positioning in images. The previous gemma 4 visiom models had both 2D-RoPE and X/Y Patch Embeddings table. Doesn't this removal 2D-Rope affect the vision capabilities of the 12B model?