
Topic Modeling with Llama 2
Create easily interpretable topics with Large Language Models


In this article, we will explore how we can use Llama2 for Topic Modeling without the need to pass every single document to the model. Instead, we will leverage BERTopic, a modular topic modeling technique that can use any LLM for fine-tuning topic representations.
BERTopic works rather straightforward. It consists of 5 sequential steps:
Embedding documents
Reducing the dimensionality of embeddings
Cluster reduced embeddings
Tokenize documents per cluster
Extract best-representing words per cluster
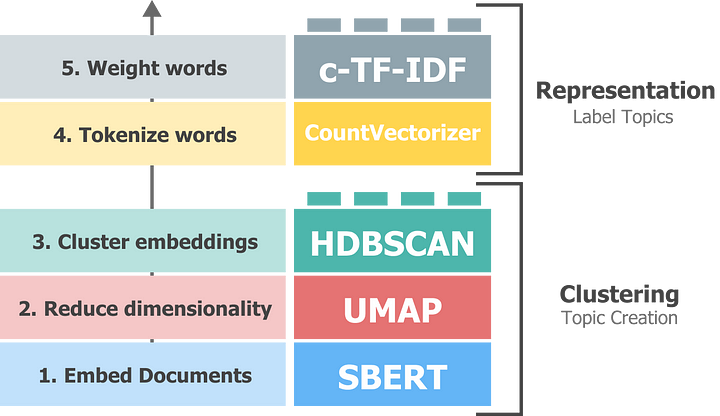
However, with the rise of LLMs like Llama 2, we can do much better than a bunch of independent words per topic. It is computationally not feasible to pass all documents to Llama 2 directly and have it analyze them. We can employ vector databases for search but we are not entirely sure which topics to search for.
Instead, we will leverage the clusters and topics created by BERTopic and have Llama 2 fine-tune and distill that information into something more accurate.
This is the best of both worlds, the topic creation of BERTopic together with the topic representation of Llama 2.

Now that this intro is out of the way, let’s start the hands-on tutorial!
We will start by installing a number of packages that we are going to use throughout this example:
pip install bertopic datasets accelerate bitsandbytes xformers adjustTextKeep in mind that you will need at least a T4 GPU in order to run this example, which can be used with a free Google Colab instance.
🔥 TIP: You can also follow along with the Google Colab Notebook.
📄 Data
We are going to apply topic modeling on a number of ArXiv abstracts. They are a great source for topic modeling since they contain a wide variety of topics and are generally well-written.
from datasets import load_dataset
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
# Extract abstracts to train on and corresponding titles
abstracts = dataset["abstract"]
titles = dataset["title"]To give you an idea, an abstract looks like the following:
>>> # The abstract of "Attention Is All You Need"
>>> print(abstracts[13894])
"""
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks in an encoder-decoder configuration. The best
performing models also connect the encoder and decoder through an attention
mechanism. We propose a new simple network architecture, the Transformer, based
solely on attention mechanisms, dispensing with recurrence and convolutions
entirely. Experiments on two machine translation tasks show these models to be
superior in quality while being more parallelizable and requiring significantly
less time to train. Our model achieves 28.4 BLEU on the WMT 2014
English-to-German translation task, improving over the existing best results,
including ensembles by over 2 BLEU. On the WMT 2014 English-to-French
translation task, our model establishes a new single-model state-of-the-art
BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction
of the training costs of the best models from the literature. We show that the
Transformer generalizes well to other tasks by applying it successfully to
English constituency parsing both with large and limited training data.
"""🤗 HuggingFace Hub Credentials
Before we can load in Llama2 using a number of tricks, we will first need to accept the License for using Llama2. The steps are as follows:
After doing so, we can log in with our HuggingFace credentials so that this environment knows we have permission to download the Llama 2 model that we are interested in.
from huggingface_hub import notebook_login
notebook_login()
🦙 Llama 2
Now comes one of the more interesting components of this tutorial, how to load in a Llama 2 model on a T4-GPU!
We will be focusing on the 'meta-llama/Llama-2-13b-chat-hf' variant. It is large enough to give interesting and useful results whilst small enough that it can be run on our environment.
We start by defining our model and identifying if our GPU is correctly selected. We expect the output of device to show a Cuda device:
from torch import cuda
model_id = 'meta-llama/Llama-2-13b-chat-hf'
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'; print(device)Optimization & Quantization
In order to load our 13 billion parameter model, we will need to perform some optimization tricks. Since we have limited VRAM and not an A100 GPU, we will need to “condense” the model a bit so that we can run it.
There are a number of tricks that we can use but the main principle is going to be 4-bit quantization.
This process reduces the 64-bit representation to only 4-bits which reduces the GPU memory that we will need. It is a recent technique and quite elegant at that for efficient LLM loading and usage. You can find more about that method here in the QLoRA paper and on the amazing HuggingFace blog here.
from torch import bfloat16
import transformers
# Quantization to load an LLM with less GPU memory
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True, # 4-bit quantization
bnb_4bit_quant_type='nf4', # Normalized float 4
bnb_4bit_use_double_quant=True, # Second quantization after the first
bnb_4bit_compute_dtype=bfloat16 # Computation type
)These four parameters that we just run are incredibly important and bring many LLM applications to consumers:
load_in_4bit - Allows us to load the model in 4-bit precision compared to the original 32-bit precision. This gives us an incredible speed up and reduces memory!
bnb_4bit_quant_type
-This is the type of 4-bit precision. The paper recommends normalized float 4-bit, so that is what we are going to use!bnb_4bit_use_double_quant
-This is a neat trick as it performs a second quantization after the first which further reduces the necessary bitsbnb_4bit_compute_dtype
-The compute type used during computation, which further speeds up the model.
Using this configuration, we can start loading in the model as well as the tokenizer:
# Llama 2 Tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
# Llama 2 Model
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
quantization_config=bnb_config,
device_map='auto',
)
model.eval()Using the model and tokenizer, we will generate a HuggingFace transformers pipeline that allows us to easily generate new text:
# Our text generator
generator = transformers.pipeline(
model=model, tokenizer=tokenizer,
task='text-generation',
temperature=0.1,
max_new_tokens=500,
repetition_penalty=1.1
)Prompt Engineering
To check whether our model is correctly loaded, let’s try it out with a few prompts.
>>> prompt = "Could you explain to me how 4-bit quantization works as if I am 5?"
>>> res = generator(prompt)
>>> print(res[0]["generated_text"])
"""
Could you explain to me how 4-bit quantization works as if I am 5?
Sure! Imagine you have a big box of crayons. Each crayon represents a different color, like red, blue, green, and so on. Now, imagine that instead of using all the different colors, we only want to use four colors: red, blue, green, and yellow. We can do this by taking all the colors and dividing them into four groups.
Group 1: Red, Blue, Green
Group 2: Yellow
Now, when we want to draw something, we can only choose one color from each group. So, if we want to draw a red apple, we would choose the red crayon from Group 1 and the yellow crayon from Group 2. This way, we can only use four colors, but we can still make lots of different things!
In the same way, when we use 4-bit quantization, we take all the numbers and divide them into four groups. Each group has a different number of bits, just like our crayon groups had different colors. Then, when we want to represent a number, we can only choose one number from each group. This way, we can represent lots of different numbers using only four bits!
"""Although we can directly prompt the model, there is actually a template that we need to follow. The template looks as follows:
"""
<s>[INST] <<SYS>>
{{ System Prompt }}
<</SYS>>
{{ User Prompt }}
[/INST]
{{ Model Answer }}
"""This template consists of two main components, namely the {{ System Prompt }} and the {{ User Prompt }}:
The
{{ System Prompt }}helps us guide the model during a conversation. For example, we can say that it is a helpful assistant that is specialized in labeling topics.The
{{ User Prompt }}is where we ask it a question.
You might have noticed the [INST] tags, which are used to identify the beginning and end of a prompt. We can use these to model the conversation history as we will see more in-depth later on.
Next, let’s see how we can use this template to optimize Llama 2 for topic modeling.
Prompt Template
We are going to keep our system prompt simple and to the point:
# System prompt describes information given to all conversations
system_prompt = """
<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant for labeling topics.
<</SYS>>
"""We will tell the model that it is simply a helpful assistant for labeling topics since that is our main goal.
In contrast, our user prompt is going to be a bit more involved. It will consist of two components, an example prompt and the main prompt.
Let’s start with the example prompt. Most LLMs do a much better job of generating accurate responses if you give them an example to work with. We will show it an accurate example of the kind of output we are expecting.
# Example prompt demonstrating the output we are looking for
example_prompt = """
I have a topic that contains the following documents:
- Traditional diets in most cultures were primarily plant-based with a little meat on top, but with the rise of industrial style meat production and factory farming, meat has become a staple food.
- Meat, but especially beef, is the word food in terms of emissions.
- Eating meat doesn't make you a bad person, not eating meat doesn't make you a good one.
The topic is described by the following keywords: 'meat, beef, eat, eating, emissions, steak, food, health, processed, chicken'.
Based on the information about the topic above, please create a short label of this topic. Make sure you to only return the label and nothing more.
[/INST] Environmental impacts of eating meat
"""This example, based on a number of keywords and documents primarily about the impact of meat, helps the model understand the kind of output it should give. We show the model that we were expecting only the label, which is easier for us to extract.
Next, we will create a template that we can use within BERTopic:
# Our main prompt with documents ([DOCUMENTS]) and keywords ([KEYWORDS]) tags
main_prompt = """
[INST]
I have a topic that contains the following documents:
[DOCUMENTS]
The topic is described by the following keywords: '[KEYWORDS]'.
Based on the information about the topic above, please create a short label of this topic. Make sure you to only return the label and nothing more.
[/INST]
"""There are two BERTopic-specific tags that are of interest, namely [DOCUMENTS] and [KEYWORDS]:
[DOCUMENTS]contain the top 5 most relevant documents to the topic[KEYWORDS]contain the top 10 most relevant keywords to the topic as generated through c-TF-IDF
This template will be filled according to each topic. And finally, we can combine this into our final prompt:
prompt = system_prompt + example_prompt + main_prompt🗨️ BERTopic
Before we can start with topic modeling, we will first need to perform two steps:
Pre-calculating Embeddings
Defining Sub-models
Preparing Embeddings
By pre-calculating the embeddings for each document, we can speed up additional exploration steps and use the embeddings to quickly iterate over BERTopic’s hyperparameters if needed.
🔥 TIP: You can find a great overview of good embeddings for clustering on the MTEB Leaderboard.
from sentence_transformers import SentenceTransformer
# Pre-calculate embeddings
embedding_model = SentenceTransformer("BAAI/bge-small-en")
embeddings = embedding_model.encode(abstracts, show_progress_bar=True)Sub-models
Next, we will define all sub-models in BERTopic and do some small tweaks to the number of clusters to be created, setting random states, etc.
from umap import UMAP
from hdbscan import HDBSCAN
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
hdbscan_model = HDBSCAN(min_cluster_size=150, metric='euclidean', cluster_selection_method='eom', prediction_data=True)As a small bonus, we are going to reduce the embeddings we created before to 2-dimensions so that we can use them for visualization purposes when we have created our topics.
# Pre-reduce embeddings for visualization purposes
reduced_embeddings = UMAP(n_neighbors=15, n_components=2, min_dist=0.0, metric='cosine', random_state=42).fit_transform(embeddings)Representation Models
One of the ways we are going to represent the topics is with Llama 2 which should give us a nice label. However, we might want to have additional representations to view a topic from multiple angles.
Here, we will be using c-TF-IDF as our main representation and KeyBERT, MMR, and Llama 2 as our additional representations.
from bertopic.representation import KeyBERTInspired, MaximalMarginalRelevance, TextGeneration
# KeyBERT
keybert = KeyBERTInspired()
# MMR
mmr = MaximalMarginalRelevance(diversity=0.3)
# Text generation with Llama 2
llama2 = TextGeneration(generator, prompt=prompt)
# All representation models
representation_model = {
"KeyBERT": keybert,
"Llama2": llama2,
"MMR": mmr,
}🔥 Training
Now that we have our models prepared, we can start training our topic model! We supply BERTopic with the sub-models of interest, run .fit_transform, and see what kind of topics we get.
from bertopic import BERTopic
topic_model = BERTopic(
# Sub-models
embedding_model=embedding_model,
umap_model=umap_model,
hdbscan_model=hdbscan_model,
representation_model=representation_model,
# Hyperparameters
top_n_words=10,
verbose=True
)
# Train model
topics, probs = topic_model.fit_transform(abstracts, embeddings)Now that we are done training our model, let’s see what topics were generated:
# Show top 3 most frequent topics
topic_model.get_topic_info()[1:4]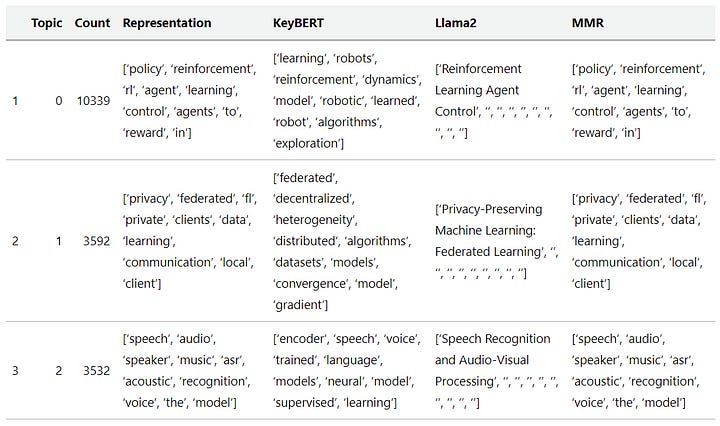
# Show top 3 least frequent topics
topic_model.get_topic_info()[-3:]
We got over 100 topics that were created and they all seem quite diverse. We can use the labels by Llama 2 and assign them to topics that we have created. Normally, the default topic representation would be c-TF-IDF, but we will focus on Llama 2 representations instead.
llama2_labels = [label[0][0].split("\n")[0] for label in topic_model.get_topics(full=True)["Llama2"].values()]
topic_model.set_topic_labels(llama2_labels)📊 Visualize
We can go through each topic manually, which would take a lot of work, or we can visualize them all in a single interactive graph.
BERTopic has a bunch of visualization functions that we can use. For now, we are sticking with visualizing the documents.
topic_model.visualize_documents(titles, reduced_embeddings=reduced_embeddings,
hide_annotations=True, hide_document_hover=False, custom_labels=True)
🖼️ (BONUS): Advanced Visualization
Although we can use the built-in visualization features of BERTopic, we can also create a static visualization that might be a bit more informative.
We start by creating the necessary variables that contain our reduced embeddings and representations:
import itertools
import pandas as pd
# Define colors for the visualization to iterate over
colors = itertools.cycle(['#e6194b', '#3cb44b', '#ffe119', '#4363d8', '#f58231', '#911eb4', '#46f0f0', '#f032e6', '#bcf60c', '#fabebe', '#008080', '#e6beff', '#9a6324', '#fffac8', '#800000', '#aaffc3', '#808000', '#ffd8b1', '#000075', '#808080', '#ffffff', '#000000'])
color_key = {str(topic): next(colors) for topic in set(topic_model.topics_) if topic != -1}
# Prepare dataframe and ignore outliers
df = pd.DataFrame({"x": reduced_embeddings[:, 0], "y": reduced_embeddings[:, 1], "Topic": [str(t) for t in topic_model.topics_]})
df["Length"] = [len(doc) for doc in abstracts]
df = df.loc[df.Topic != "-1"]
df = df.loc[(df.y > -10) & (df.y < 10) & (df.x < 10) & (df.x > -10), :]
df["Topic"] = df["Topic"].astype("category")
# Get centroids of clusters
mean_df = df.groupby("Topic").mean().reset_index()
mean_df.Topic = mean_df.Topic.astype(int)
mean_df = mean_df.sort_values("Topic")Next, we will visualize the reduced embeddings with Matplotlib and process the labels in such a way that it is visually more pleasing:
import seaborn as sns
from matplotlib import pyplot as plt
from adjustText import adjust_text
import matplotlib.patheffects as pe
import textwrap
fig = plt.figure(figsize=(20, 20))
sns.scatterplot(data=df, x='x', y='y', c=df['Topic'].map(color_key), alpha=0.4, sizes=(0.4, 10), size="Length")
# Annotate top 50 topics
texts, xs, ys = [], [], []
for row in mean_df.iterrows():
topic = row[1]["Topic"]
name = textwrap.fill(topic_model.custom_labels_[int(topic)], 20)
if int(topic) <= 50:
xs.append(row[1]["x"])
ys.append(row[1]["y"])
texts.append(plt.text(row[1]["x"], row[1]["y"], name, size=10, ha="center", color=color_key[str(int(topic))],
path_effects=[pe.withStroke(linewidth=0.5, foreground="black")]
))
# Adjust annotations such that they do not overlap
adjust_text(texts, x=xs, y=ys, time_lim=1, force_text=(0.01, 0.02), force_static=(0.01, 0.02), force_pull=(0.5, 0.5))
plt.axis('off')
plt.legend('', frameon=False)
plt.show()
Thank you for reading!
If you are, like me, passionate about AI and/or Psychology, please feel free to add me on LinkedIn, follow me on Twitter, or subscribe to my Newsletter. You can also find some of my content on my Personal Website.
Update: I uploaded a video version to YouTube that goes more in-depth into how to perform Topic Modeling with Llama 2
I really enjoy reading your post. It's intuitive and easy to follow. Thank you for sharing your work!
is it not viable to let the LLM do the entire task of topic modelling instead of just the topic representation at the end? wonder if this would give better results.